The hidden inter-availability zone data transfer costs of running Kubernetes in AWS

Let me first say that I am a massive AWS fan. If I had an endless pit of money, I would literally run everything in AWS. However, time and time again, you hear stories of people leaving huge instances running for a few days/weeks or being caught out by data transfer costs resulting in a massive bill at the end of the month.
When it comes to data transfer, it gets even more complicated when you consider where the traffic is coming from and where it's going. This is particularly troublesome when it comes to running Kubernetes (EKS) across multiple availability zones.
What is an availability zone (AZ going forward)?
Before I go further, I think it is apt to mention what an AZ is. In AWS terms, there are two important notions that often expose you to data transfer costs. Regions, which are spread across the globe and offer any number of the AWS-provided services. The regions are on almost every continent on the globe with some continents having plenty of them. They are the core to where data and compute is located.
The next important notion is AZs. An AZ is an isolated independent geographically separated data centre that belongs to a region. Typically, regions have three of these AZs but could have more.
Aside: for me, this is what differentiates AWS from all the other public cloud providers. Each region comes, by default, with complete isolation of all AZs with a guarantee of how they are isolated (distance, elevation, independent power, independent connectivity, independent management etc).
Sounds great, don't see the problem?
Remember I said data transfer often catches people out. When deploying your workloads in what is typically an HA setup (surviving an AZ outage requires you to run your workloads across AZs) you inevitably incur inter-AZ data transfer costs. Often, this is acceptable when doing replication or the odd cross-AZ routing.
However, when it comes to EKS and particularly a load balancer (Network Load Balancer coupled with a Kubernetes Ingress) things can escalate very quickly.
Without understanding all the options, you can quickly increase inter-AZ traffic by up to three
times for each request going to a pod sitting in your cluster. This doesn't include replication or movement of data which in our case included both Elastic replication across AZ and moving shards to warm Elastic instances.
Arrows all the way down!
To illustrate what could happen with only a handful of options either enabled or not enabled, I've created a diagram. Warning: there are a lot of arrows.
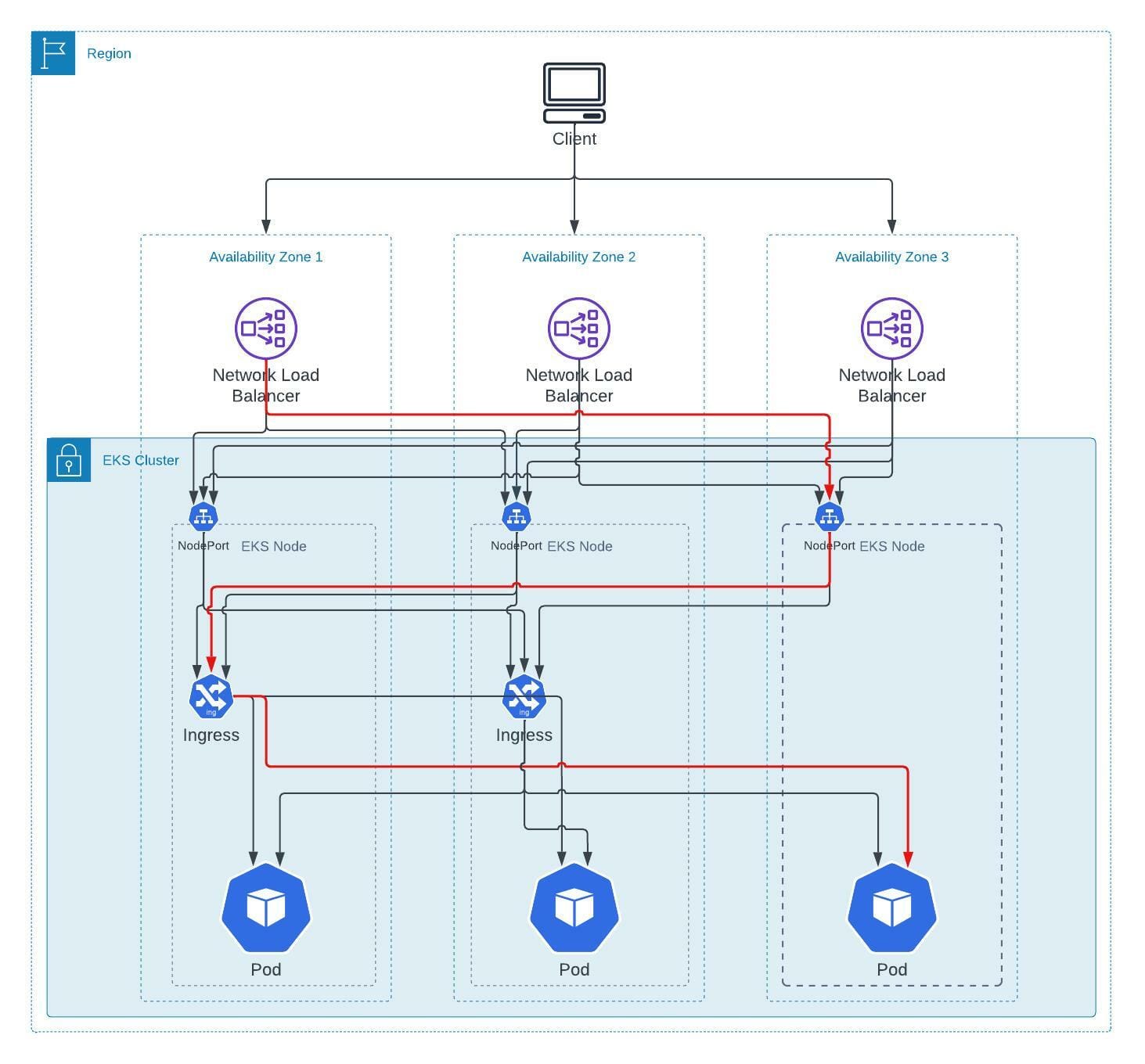
The red arrow illustrates the worst-case movement of data coming from outside the load balancer and reaching a replicated Elastic shard. The data is not 1:1 all the way down but the illustration remains quite important.
So far, all you've given me is problems, what is the solution?
Disable cross-availability zone load balancing
There is a feature with Network Load Balancers (NLB) where the load balancer can send traffic across AZs. This is useful if what is receiving traffic is not spread across every or any availability zone. It means that a target for a specific instance of the NLB can be in a different AZ which means that this will incur inter-AZ data transfer costs.
Assuming that you have a cluster that has nodes spanning across all the AZs you've decided to run in, you can then disable cross-availability zone load balancing to force the load balancer to send traffic to targets in the same AZ. Typically the targets are the worker nodes in the cluster which brings us to problem two.
Configure Ingress Nginx to run in IP mode
By default the AWS LB Controller and whatever ingress controller you're using (in our case, Ingress Nginx NOT Nginx Ingress...) run in instance mode. This means that a NodePort is exposed on the instances which will forward traffic on to the load balancer type service in Kubernetes. This presents an additional network hop and another opportunity for network traffic to be routed across AZs.
To limit this, you can configure the ingress controller to run in IP Mode (note you configure the ingress controller to run in this mode which the AWS LB Controller honours). To do this, you simply need to annotate the service with `service.beta.kubernetes.io/aws-load-balancer-type: nlb-ip`.
It's important to note, that your network CNI needs to be configured to have routable pods (default in the AWS VPC CNI) which exposes the pods with routable IPs on the secondary interfaces of an EC2 instance.
The important outcome of this configuration is that instead of the instances being targets for the load balancer, the ingress controller pods become the targets resulting in one less network hop and, importantly, one less opportunity for traffic to traverse from one AZ to another..
Enable topology-aware routing hints in Kubernetes
We still have one issue with traffic routing across AZs and this is native to Kubernetes. Unfortunately, there can be no assurance of the same AZ traffic routing and this is by design. A service which has endpoints in Kubernetes, simply round robins to each endpoint regardless of which AZ it is in. This means that as long as an endpoint is available, Kubernetes will send traffic to it which solves HA requirements.
However, in our case, we would prefer traffic to stay within the same AZ if possible and if it is safe. In Kubernetes, from version 1.23, a new annotation on services called Topology Aware Hints allows you to make the EndpointSlice Controller consider topology when creating endpoints. It will only do so if it's safe to do it (enough endpoints across the zones etc.).
It's important to note that this is a hint. We still want to avoid routing all traffic to a single pod purely because it's in the same AZ as we might, by chance, get one overloaded pod and two idling pods. Ultimately, you should see a reduction in traffic going across AZs.
In conclusion...
We can ignore the fact that Elastic, in our case, would replicate because this is by design to ensure safety in case an AZ does fall over and to make sure Elastic still operates in that case. We can calculate this amount as it's pretty much a 1:1 relationship with the size of a shard pretty much equaling what we are transferring across AZ.
The attempt here is to remove "hidden" AZ data transfer costs and not really remove all data transfer costs.


Comments ()